
데이터 엔지니어가 바라본 2020 AWS 리인벤트(re:Invent) What's New - Week 1 (Part 1)


올해도 어김없이 최대 규모의 클라우드 컨퍼런스 중 하나인 AWS re:Invent의 시즌이 돌아왔습니다. 이전과는 다르게 올해는 코로나19라는 특수한 상황으로 인해 모두 온라인으로 진행되고, 3주에 나누어 AWS의 새로운 기능들을 소개하고 여러가지 기술 세션들을 진행하게 됩니다.
이 시즌에는 행사가 시작하기 몇 주 전부터 행사가 끝나고까지 무수히 많은 새로운 서비스들과 기능들이 쏟아져 나오기 때문에 그 중에서 관심있는 소식만 찾는 것도 쉬운 일이 아닌데요, 앞으로 3주 동안 데이터 엔지니어의 관점에서 올해 리인벤트의 흥미로운 소식들을 정리해 보려고 합니다.
Amazon Managed Workflows for Apache Airflow (MWAA)
가장 핫한 소식 아닐까 싶습니다. 이제는 De-facto standard가 된 워크플로우 오케스트레이션 엔진인 Apache Airflow의 AWS 매니지드 서비스입니다. 이미 경쟁사인 GCP에서는 Cloud Composer 라는 이름으로 서비스 중이기도 합니다. 개인적으로 클라우드 컴포저가 썩 편하지 않다고 생각하기 때문에, 출시에 대한 소문이 무성할 때 부터 어떤 식으로 제공될 지 매우 궁금했습니다.
첫인상은 생각보다 단순화되어 나쁘지 않은 느낌입니다. 내부적으로는 Cloud Composer와 비슷하게 EKS에서 운영되는 것으로 추측됩니다. 가장 흥미로운 점은 DAG, 플러그인, requirements.txt 등을 모두 S3에 올려 사용한다는 점입니다. DAG를 읽는 메타데이터 오퍼레이션이 주기적으로 많이 일어나기 때문에 읽어야 하는 파이썬 파일이 많아지는 경우가 우려되긴 합니다만, 2.0에서 크게 개선되는 Scheduler HA와 DAG Serialization 등을 사용하면 크게 무리가 없을 것 같습니다. (참고: Introducing Airflow 2.0 | Astronomer)
다만, 다양한 종류의 인스턴스 환경(Pricing 참고)이 아직 제공되지 않는다는 점과, 가격이 약간 비싸다는 것이 아쉽습니다. 개인적으로는 여러가지 많은 커스텀을 해서 사용하기 때문에 매니지드 서비스를 활용하기 어렵습니다만, 단순 Task Trigger 기능만 활용하는 등 가볍게 사용하시는 경우 프로덕션에서 활용하기에는 충분해 보입니다.
Amazon S3 now delivers strong read-after-write consistency automatically for all applications
단연코 가장 중요하고 엄청난 소식 중 하나입니다. S3에서 드디어 GET, PUT, LIST 및 메타데이터 오퍼레이션에 strong read-after-write consistency가 보장된다는 소식입니다.
분산 시스템은 기본적으로 그 특성 때문에 강력한 일관성을 제공하는 것이 어렵고, 일반적으로 결과적 일관성 (Eventual consistency)을 보장합니다. 관련된 재미난 그림이 있어 가져왔습니다.

비슷한 예로 DynamoDB 역시 기본적으로는 결과적 일관성을 보장하고, Strongly Consistent Reads의 경우 응답시간이 길거나 여러가지 제약사항이 있습니다. S3 역시 거대한 분산 저장 시스템이기 때문에 결과적 일관성 모델을 제공해왔습니다. 그래서 Spark 등으로 S3 파일을 쓴 직후에, 바로 다시 읽거나 목록을 조회하면 파일이 누락되는 등의 일관성이 깨지는 문제가 발생할 수 있었습니다. 이를 방지하기 위해 EMR에서는 EMRFS Consistent View, 오픈소스로는 S3Guard 등의 솔루션이 필요했습니다. EMRFS는 내부적으로 DynamoDB를 함께 사용하여 일관성을 보장하는 식으로 구현되어 있습니다.
하지만 이제는 강력한 일관성이 기본적으로 S3에 제공되기 때문에 이런 걱정을 하지 않아도 됩니다. 정말 중요하면서도 반가운 발표입니다. 개인적으로 이것이 어떻게 구현되었는지가 매우 궁금한데, 추후 딥 다이브 세션이나 자료가 공개되었으면 좋겠습니다.
S3에 대해서 이야기해본 김에 S3와 관련된 소식을 몇 가지 더 살펴봅니다.
Amazon S3 adds support for multiple destinations in the same, or different AWS Regions
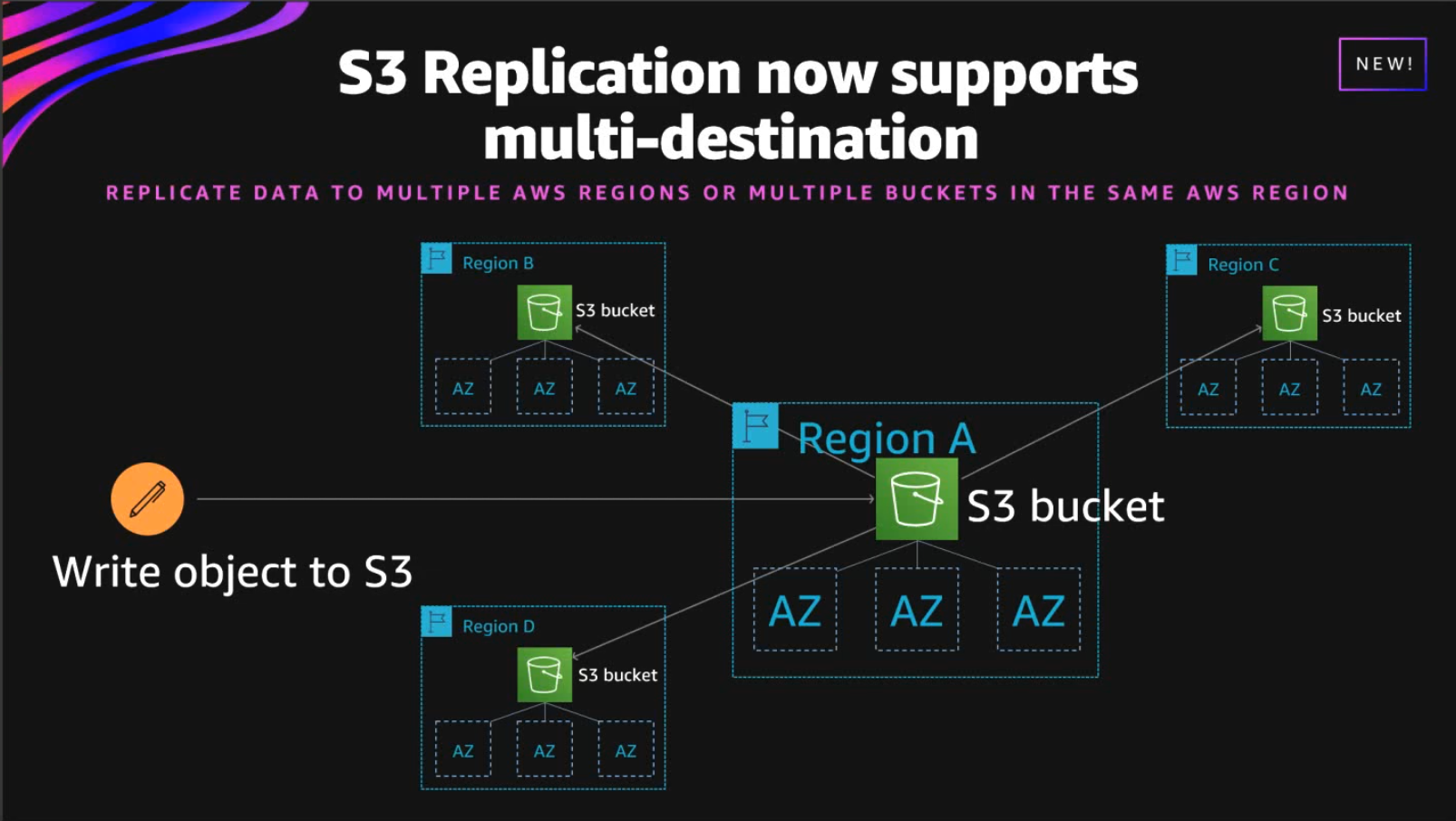
이제 S3 replication의 목적지가 되는 버킷을 2개 이상 지정할 수 있게 되었다는 소식입니다. 기존에는 2개 이상의 버킷에 복제하기 위해서는 Lambda 등을 사용하여 직접 구현해야 했는데요, 이제는 그런 수고를 들이지 않고도 안정적으로 multi-destination, cross-region, cross-account replication을 모두 할 수 있게 되었습니다.
Amazon S3 Replication adds support for two-way replication
이제 S3 replication에서 단방향 복제가 아닌 양방향(two-way, bi-directional) 복제가 가능하게 되었습니다.
Amazon S3 Bucket Keys reduce the costs of Server-Side Encryption with AWS Key Management Service (SSE-KMS)
S3 암호화 방식으로 SSE-KMS(Server-side encryption with AWS KMS)를 사용하는 경우 모든 오브젝트에 대해 암호화/복호화를 할 때 KMS 키를 사용하기 때문에 KMS 요청이 매우 많이 발생하게 됩니다. 새로 출시된 S3 Bucket Key는 S3 내부적으로 KMS 키를 사용하여 특정 버킷에 대해 일정 시간 동안 유효한 키를 생성해 저장해놓고, 암호화/복호화에 이를 사용해 KMS 요청을 매우 줄일 수 있게 됩니다.
DynamoDB
Amazon DynamoDB S3 Export
Reinvent 몇 주 전에 나온 기능입니다만, 많은 분들이 기다려왔던 기능이라 소개해 보려고 합니다. 기존에는 EMR이나 Glue를 이용하면 테이블을 덤프할 수 있었지만, 직접 스캔하는 방식이기 때문에 시간이나 비용, 그리고 부하 측면에서 문제가 있었습니다. 이번에 발표된 기능은 증분 백업(PITR)을 내부적으로 사용하기 때문에 실제 DB에 부하 없이 매우 빠르게 진행됩니다. PITR이 켜져 있어야 하며, 실제로 S3에 export 된 백업의 크기로 과금됩니다.
내부적으로 테스트해 본 결과 속도는 나쁘지 않았습니다만, DynamoDB JSON 형식으로 추출되기 때문에 제대로 활용하기 위해서는 추가 작업이 필요하다는 점이 아쉽습니다.
Amazon DynamoDB Change Data Capture(CDC) for Kinesis Data Streams
DynamoDB의 CDC 스트림은 내부적으로 Kinesis Stream을 사용한다고 알려져 있습니다(정정: 내부 엔지니어와 이야기해본 결과 API는 호환되지만 별도의 구현이라고 합니다). 그래서 실제로 Kinesis Stream API와 호환되고, Describe API를 호출해보면 샤드의 ID도 확인할 수가 있었습니다. 하지만, 최대 2개의 컨슈머만 사용할 수 있고, 스트림이 켜져있는 테이블의 경우 최대 WCU에 제한이 있었습니다. 하지만 Kinesis를 사용하면 일반 Kinesis Stream 스펙을 동일하게 100% 사용할 수 있게 됩니다.
주의할 점도 있는데요, Kinesis Stream을 사용하는 만큼 WCU에 맞추어 샤드를 scale 해줘야 하고, Kinesis의 PutRecords를 이용하여 배치로 변경사항을 push하기 때문에 레코드의 순서가 보장되지 않아 엄밀한 ordering을 위해서는 함께 제공되는 timestamp를 참조해야 합니다 (Kinesis의 PutRecords는 레코드 간의 순서가 보장되지 않습니다). 뿐만 아니라 간혹 발생할 수 있는 중복에 대해서도 처리해줘야 합니다. 하지만 이런 사항들은 데이터 세계에서는 일반적인 요소들이기 때문에 Kinesis Stream를 활용할 수 있는 장점이 훨씬 크겠네요.
Amazon MSK now offers consumer lag metrics and select topic-level metrics for free
AWS 매니지드 카프가 서비스인 MSK에서 이제 Open Monitoring을 사용하지 않아도 토픽의 파티션 레벨의 컨슈머 lag 메트릭을 확인할 수 있게 되었습니다. 추가로 몇 가지 메트릭들이 이제 무료로 제공됩니다.
Amazon Elasticsearch Service announces support for Elasticsearch version 7.9
AWS 매니지드 Elasticsearch에서 이제 ElasticSearch 7.9 버전을 사용할 수 있게 되었습니다.
Amazon DevOps Guru in Preview, an ML-powered cloud operations service to improve application availability for AWS workloads
Amazon.com에서의 경험을 바탕으로 사용자의 AWS 계정에 있는 리소스들을 머신러닝을 사용하여 분석하고, 응답시간 지연, 에러 레이트 상승 등의 anomaly(이상상황)에 대해 자동으로 알려주는 서비스입니다. 이 영역은 데이터독과 같은 모니터링 서비스 회사부터 그리고 최근에 이쪽으로 사업을 확장하고 있는 elastic 등에서도 앞다투어 제공하려고 하는 서비스인데요. 아마존에서의 경험을 녹여서 만든 제품이라고 하니 기대가 됩니다.
마무리
몇 가지 굵직한 소식들과 간단한 소식들을 짚어봤습니다. 이미 많은 소식들을 둘러본 것 같은데 아직 1주차의 절반 정도 밖에 오지 못했네요. 다음 편에서는 컨테이너와 서버리스, EC2를 중점적으로 살펴봅니다.